
Duplicate content is the most common issue that can be seen on a website during the on-page audit. Websites might struggle to perform as per the expectations if they have duplicate content on it. We will discuss this in detail in this blog post along with the probable solutions which one can follow to resolve the issues.
What is Duplicate Content?
When the same piece of information is present on more than one page/location on the internet it can be considered as duplicate content. If it’s present on more than one page of the same website, it will fall under internal duplicity and when the same piece of content is present on any other website other than yours, it can be called as external duplicity.
How to Detect Duplicate Content?
The main question that comes in the mind of a website owner is how to identify whether the website has duplicate content or not. It’s always better to use automated tools available on the internet to detect the duplicate content if you are not sure where it’s present on your website. Below are some of them that can be used to identify it:
- Siteliner: This tool can provide you the information of duplicate content present within the website. All you need to do is to enter the URL of your website and wait for it to generate the report. The generated report will have a number of metrics and go to the duplicate content part to know the pages which are identical to each other or may be some portion common in them.
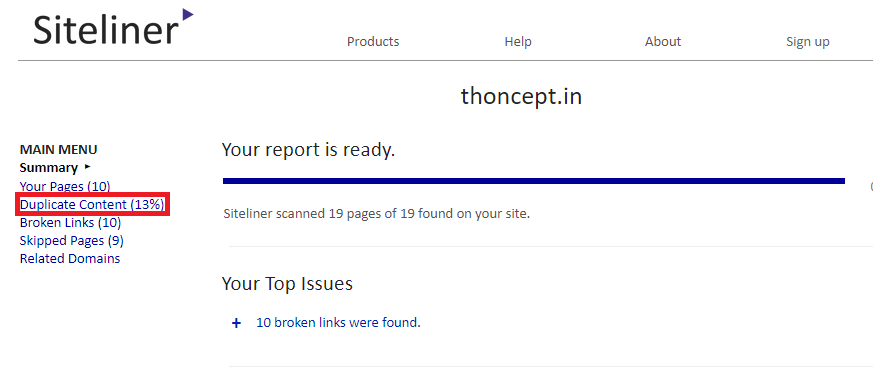
Note: Free version of the siteliner tool allows you to crawl up to 250 pages so if your website has more than 250 pages then you can opt for their premium services.
- Copyscape: This tool is very useful in detecting the external duplicity i.e. it will list down the web pages which are having similar content. They are also offering a premium version.
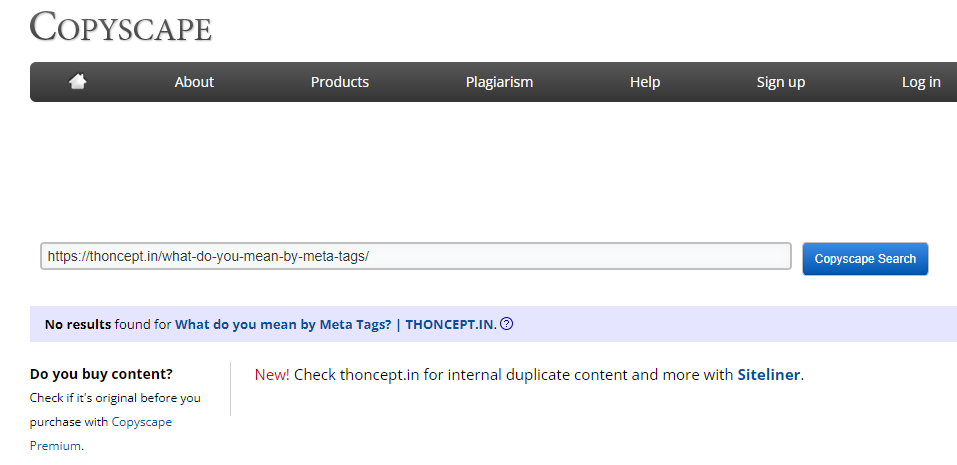
There are more free/premium tools available on the internet which can be used to identify the issues. Now, it’s a turn to resolve the duplicate content issues once you have identified it using these tools.
How to Resolve Duplicate Content Issues?
This is a very crucial step and before moving ahead with the steps to resolve the duplicity, one should understand the purpose/cause of it, i.e. the solution is going to be based on the cause of the duplicity. Below are some of the ways listed which can be used cautiously according to the situation:
For example – Dynamic URL’s on a product website generated through different filters. www.justanexampletoshowcanonical.com/product/white-tshirt www.justanexampletoshowcanonical.com/product?color=white&type=tshirt www.justanexampletoshowcanonical.com/product?color=white&type=tshirt&size=xl

The best approach is to detect the duplicate content and try to get rid of the same using the above methods.