
Robots.txt is a text file uploaded to the root folder of the website to tell crawlers and robots which pages they can access on the website i.e. with the help of this file you can tell them which pages you would like them to visit and which pages you do not want them to visit.
Why there is a need to add Robots.txt file?
You can prevent crawlers and robots from accessing certain parts of your website through robots.txt. It can be a complete folder, a media file, or a web page. You can prevent them from crawling any of these. You can specify one or more rules in robots.txt to block or allow crawlers access to specific locations/paths on your website.
Where to add Robots.txt?
Location of the robots.txt file is very crucial and important. It has to be uploaded to the root folder of the website, i.e. in the main directory, as robots and crawlers will look for that file there. They will check your website to see if it has a robots.txt file at www.putyourwebsitedomainhere.in/robots.txt. If they do not find robots.txt in the main directory, they will assume that the file has not been added and they can proceed with the crawling process.
Syntax of Robots.txt
Below is the syntax of a simple robots.txt file
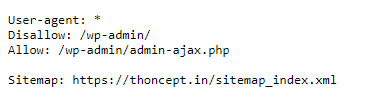
In most cases, you will find the directives below in the robots.txt file.
- User-agent
- Allow
- Disallow
- Sitemap
Let’s discuss the above in detail now:
User-agent: This is used to specify the crawlers for which the rule is applied. If you want the rule to apply to all crawlers, then use *. Below is the syntax for that.
User-agent: *
Whatever rule you are going to add after the above syntax it will be applied to all crawlers i.e. whether you want to add disallow or allow, it will be applicable to all crawlers and bots.
Disallow: This will be used to tell bots and crawlers not to access specific pages, files, or parts of your website. For example, if you want crawlers to refrain from accessing the sample page of your website, you can use the following syntax to instruct them:
User-agent:*
Disallow: /sample-page
Allow: This will be used to specify the page or directory that crawlers and bots are allowed to access. This is more useful when you want crawlers to access a specific page in a directory instead of the entire directory. For example, if you want them to access /directory/sample-page.html, but access to /directory/ is disallowed, you can use the following syntax to instruct them:
User-agent: *
Disallow: /directory/
Allow: /directory/sample-page.html
Sitemap: This will be used to provide location of the sitemap i.e. the sitemap of the website is located at www.thoncept.in/sitemap.xml
Things to Remember While Creating Robots.txt File
- Filename: Make sure to name robots file of your website as robots.txt.
- Location to add: Always add a robots.txt file in the root folder of your website and do not place it at any other location like in subdirectory etc. A subdomain can have a separate robots.txt file, i.e. subdomain.yourmaindomain.com and yourmaindomain.com can have their files separately.
- Make sure to define one directive per line. For example, if you want to prevent crawlers from accessing two pages of your website, you can disallow them in two lines as shown below:
User-agent: *
Disallow: /sample-page.html
Disallow: /sample-page-2.html